
Smurfs and Ghosts
Why systems that rank by outcomes misclassify skill and what behavior reveals instead

A few years ago, in her early fifties, my wife joined a beginner coed recreational soccer league. Most of the players were like her, returning to the sport after decades away. The league was designed to be low pressure, a place where people could learn, get some exercise, and enjoy the game without the intensity of more competitive divisions. It worked that way for a while. Then the games began to shift. The men on both teams started playing each other at a much higher level. The pace increased, the physicality increased, and the competitive energy rose with it. No one intended harm, and no one behaved maliciously. They simply played the way people tend to play once a game begins to matter.
In her final match of the season, my wife was defending when an opposing striker took a hard shot on goal. The ball struck her squarely in the wrist and broke it. Her wrist, that is, not the ball. The young player who took the shot felt terrible afterward. He had not been reckless, and he certainly had not meant to injure anyone. The problem was not individual behavior. It was that the environment had drifted into something it was never designed to be. The league was labeled “beginner,” but the actual level of play had moved far beyond that category.
Nothing came of it. No rule changes, no discussions, no adjustments to the league structure. Everyone simply moved on. And that, in its own way, is the point. Systems drift quietly. They rarely announce that something has gone wrong.
How Classification Systems Drift
If you have spent time in competitive environments, you have seen this pattern in many forms. Golf handicaps, chess Elo ratings, online game ladders, and weight classes in combat sports all attempt to sort people into tiers using outcomes like wins and losses. These systems work reasonably well most of the time, but they are vulnerable to predictable distortions. Incentives shape behavior. Experienced players return to beginner zones in online games. Fighters cut weight to compete against smaller opponents. People respond to the structure they are placed in, whether strategically or incidentally.
The important point is that systems do not simply measure behavior. They influence it. When the incentives embedded in a system diverge from the system’s intended purpose, drift begins. Most of the time the drift is small enough that the system still functions. Occasionally, the mismatch becomes obvious.
The Limits of Outcome‑Based Measurement
Most ranking systems treat skill as if it were directly measurable. You win and your rating goes up. You lose and it goes down. But skill is not directly observable. It is a latent construct, a set of cognitive and behavioral processes that produce outcomes. A useful way to think about this is to imagine skill as temperature before thermometers existed. You could feel it, you could guess at it, and you could compare one situation to another, but you could not measure it directly. You needed indicators that reliably revealed what was happening underneath.
Outcomes are not those indicators. They are influenced by opponent strength, context, noise, and in many systems, enforced win rate equilibrium. What these systems are doing is not measuring skill. They are approximating it. Most of the time the approximation is good enough, until it is not.
When Approximation Breaks
In StarCraft II, Bronze league is intended to represent the lowest level of play. Players at that level typically show minimal use of advanced mechanics. They rarely use control groups, struggle with multitasking, and operate at relatively low speeds. But when I examined behavioral data, not outcomes but how people actually play, a different picture emerged. A subset of “Bronze” players behaved nothing like beginners. They used control groups continuously, managed multiple tasks at once, and executed early game actions with consistency. These are learned skills, not beginner behaviors.
One of the clearest indicators was control group recall rate, the number of times a player re-selects pre-assigned unit groups per minute. True Bronze players tend to use control groups rarely, if at all. But some “Bronze” players were using them constantly. A threshold around eighty recalls per minute, roughly the upper tail of the Bronze distribution, separates typical behavior from something else.
Figure 1 shows this pattern clearly. Most Bronze players cluster near zero, while a distinct secondary tail reveals a population whose behavior is inconsistent with beginner level play. The important point is not the threshold itself. It is that the distribution does not behave like a single population.
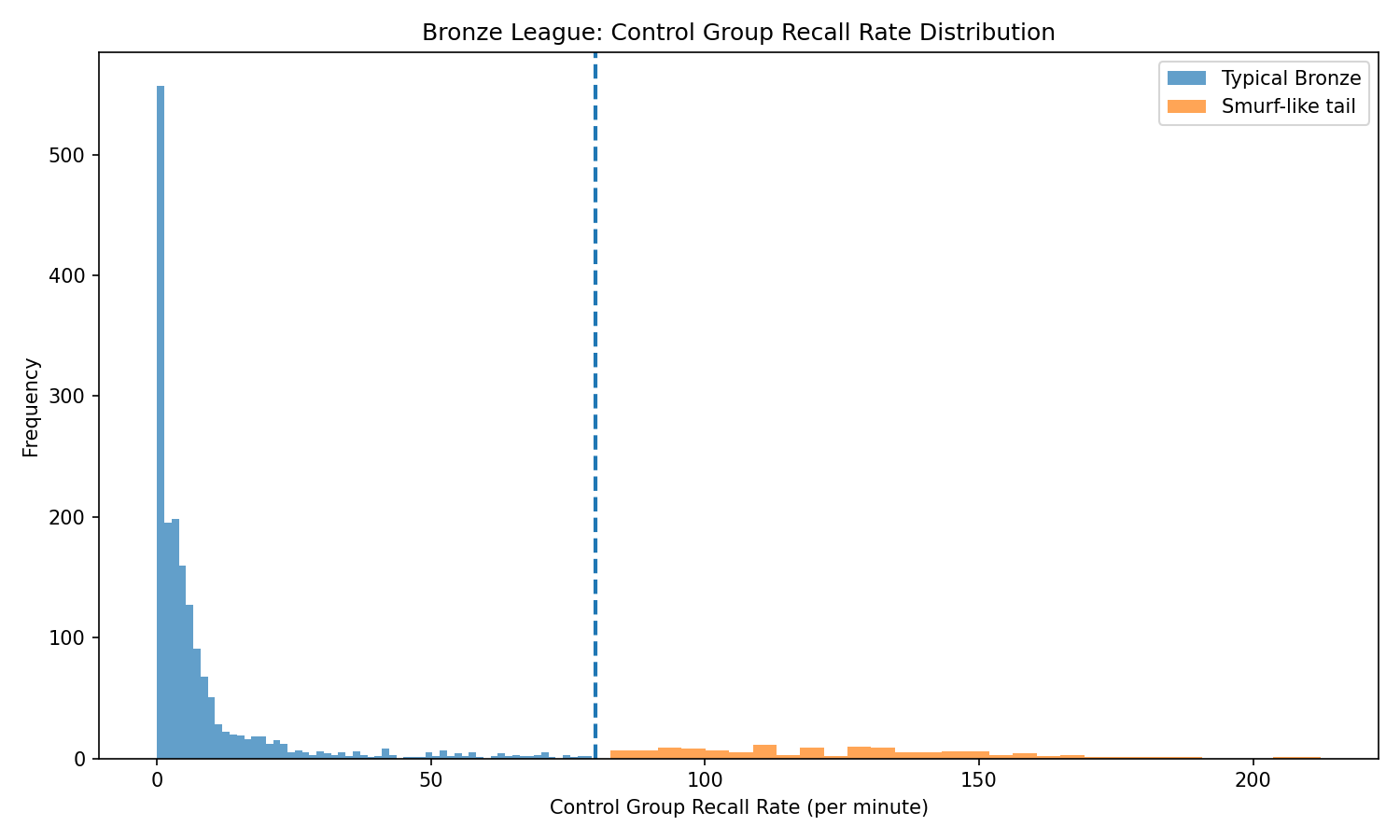
Figure 1. Control group recall rate within Bronze league.
Restoring Structure
When this small set of high recall Bronze observations is removed, the structure of the system changes. Before filtering, Bronze appears inflated relative to its position in the skill hierarchy. After filtering, the expected progression re emerges. The leagues fall back into a coherent order.
Figure 2 illustrates this shift. The “before” line shows Bronze sitting anomalously high. The “after” line shows a smooth, monotonic increase from Bronze through Grandmaster. This is not a minor adjustment. It is the difference between a system that behaves coherently and one that does not.
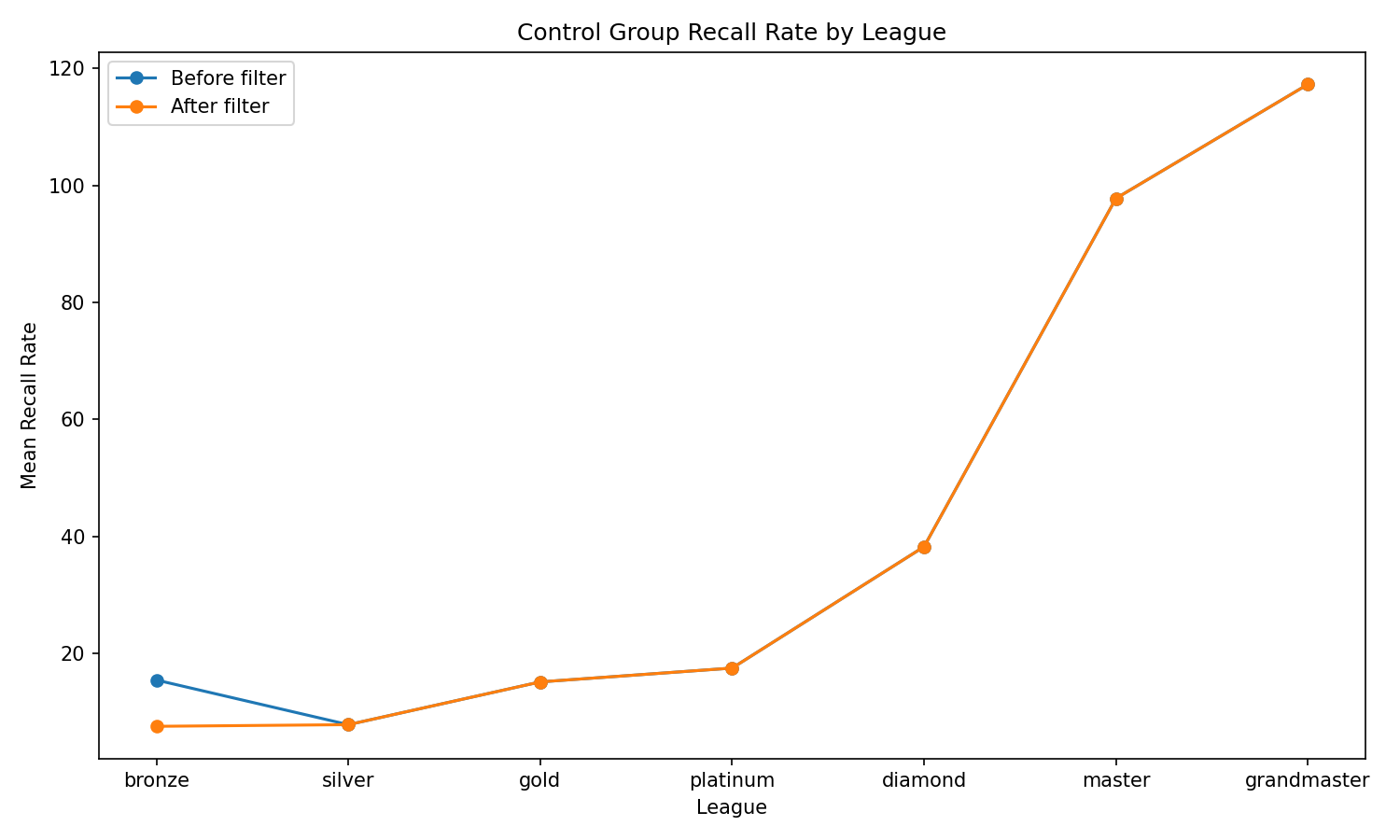
Figure 2. Mean control group recall rate by league, before and after filtering. A small number of anomalous observations distort the structure; removing them restores the expected monotonic pattern.
Smurfs and Ghosts
Two types of classification error appear in systems like this. Smurfs are players placed below their true skill level. They appear weaker than they are. Ghosts are players whose true ability is masked by noise or context. Their skill is present, but not clearly visible. Neither category requires bad intent. Both arise naturally when systems rely on imperfect signals.
Why This Matters Beyond Games
This pattern is not limited to esports or recreational leagues. It appears anywhere outcomes are used as a proxy for underlying ability. Students are placed in the wrong math track because a single test score hides the reasoning strategies they actually use. Employees are evaluated by quarterly results that obscure the behaviors that produce long term performance. Athletes are sorted into divisions that reward the wrong signals. Even medical triage systems sometimes misclassify patients because the observable outcome is not the best indicator of the underlying condition.
Whenever a system relies on outcomes alone, it will misread people. Behavioral measurement reveals what outcomes hide.
Measuring Behavior Instead of Outcomes
Instead of relying solely on outcomes, we can measure the behaviors that generate them. Using an item response theory model, I estimated which behavioral features actually distinguish players across skill levels. The model identifies the features that most effectively separate players along the latent ability continuum.
Figure 3 shows the discrimination strengths of these features. Measures of decisional latency and control group usage are among the strongest signals in the model. These are not arbitrary metrics. They are the behaviors that most clearly differentiate players across the full range of performance.
Up to this point, the problem has been one of classification. Outcome based systems will occasionally place people in the wrong category, and when that happens, the structure of the system begins to break down. Behavioral measurement improves classification by distinguishing between players who appear similar on the surface but operate at very different underlying levels.
But classification is only the first layer
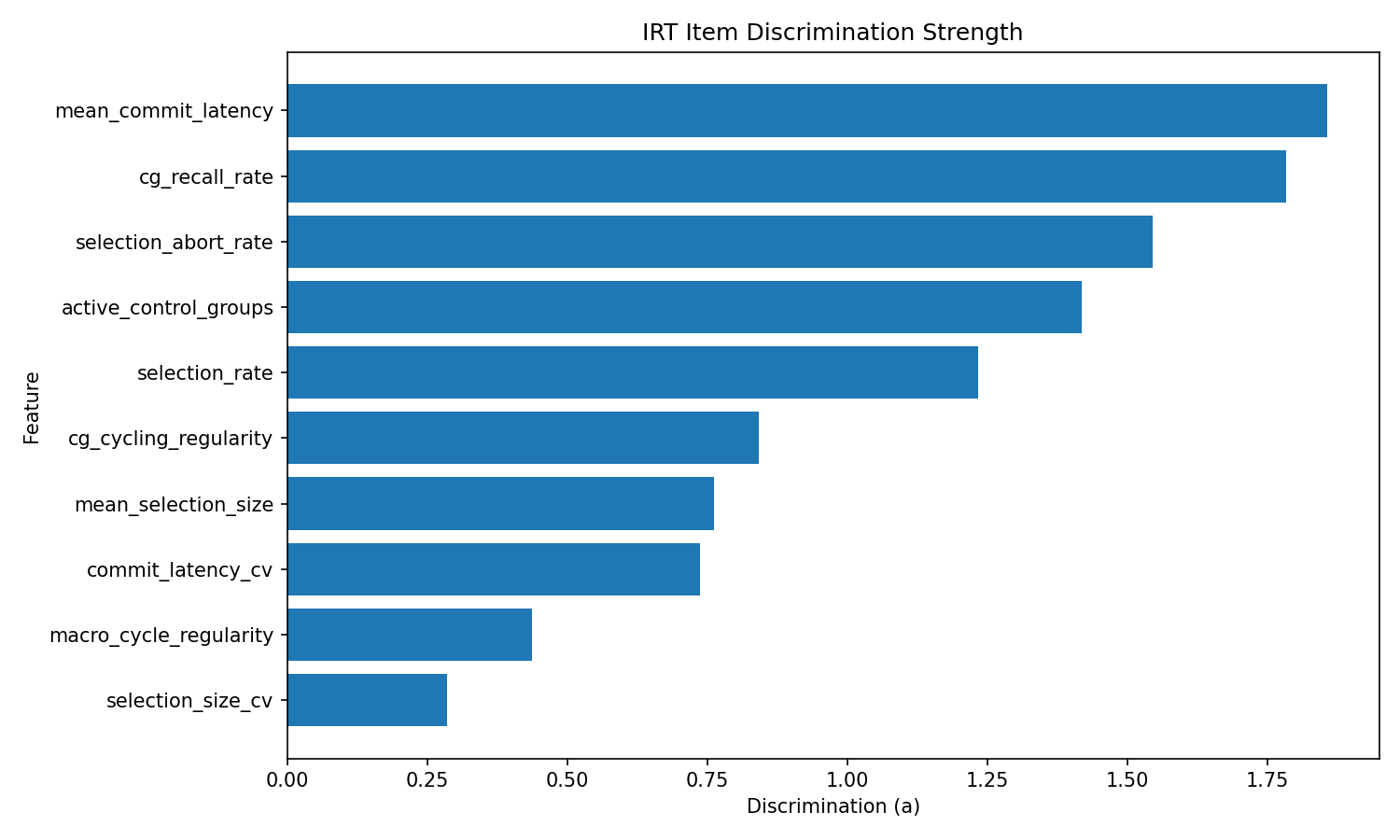
Figure 3. Item discrimination parameters from the IRT calibration. Measures of decisional latency and control group usage are among the strongest signals in the model.
Skill Moves Before Outcomes Do
When these same behavioral signals are tracked over time, a deeper pattern emerges. Skill does not move in lockstep with performance. Sometimes the underlying behaviors improve before any change appears in outcomes. Other times, performance temporarily declines during periods of skill acquisition, only to recover later at a higher level. The same signals that help identify when a player does not belong in a given category can also indicate when change is already underway, before it becomes visible in rank or results.
This introduces a different question. It is no longer just where someone belongs, but how systems evolve over time, and how those changes become measurable before they appear in outcomes.
Meanwhile, Outside the Model…
When my wife’s wrist healed, she went back to her normal routines. The league continued as it always had. Nothing changed, because nothing in the system signaled that anything needed to. The drift had been gradual, familiar, and easy to overlook. That is how most systems fail. Not with a dramatic collapse, but with a quiet mismatch between the labels we use and the reality underneath.
Outcome-based systems tell us who won and who lost. Behavioral systems tell us who is learning, who is improving, and who is already out of place long before the results make it obvious. Outcomes describe the past. Behavior describes the present. And in any domain where people are trying to grow, compete, or simply participate safely, the present is what matters most.
In our case, the present kept moving. The league did not change, because nothing in the system indicated that anything needed to. The mismatch was gradual, familiar, and easy to ignore. That is how most systems fail. Not with a dramatic collapse, but with a quiet divergence between the labels we use and the reality underneath.
And that is the deeper limitation of outcome-based systems. They can only tell us what has already happened. They cannot tell us what is changing while it happens.
References
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee’s ability.
Embretson, S. E., & Reise, S. P. (2000). Item Response Theory for Psychologists.
Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk.
Lord, F. M. (1980). Applications of Item Response Theory to Practical Testing Problems.
Rasch, G. (1960). Probabilistic Models for Some Intelligence and Attainment Tests.