
The Practicing Player
What 6000 StarCraft 2 replays worth of behavioral data say about my ladder improvement

The Practicing Player
What 5,889 games of behavioral data say about getting better before the ladder knows it
In May 2025, I changed how I practiced StarCraft II.
I have been playing StarCraft continuously since 2000, twenty-six years across two games and more ladder seasons than I have bothered to count. The dataset analyzed in this post covers the last five years of that history, not because I stopped playing before that, but because five years is what my current hard drive holds. My rating across that window has oscillated between 1,827 and 2,507 MMR, never breaking into Platinum, never dropping out of Gold for long. A plateau with texture but no trajectory.
The change was deliberate, and it had a specific inspiration. I had been watching the Bronze to Grandmaster series produced by PiG, Winter, and uThermal, three of the most entertaining and analytically rigorous SC2 content creators working today. The through-line across all three series is the same: sustainable improvement at any league level comes from building mechanical and macro fundamentals first. Production consistency. Supply management. Orbital Command discipline. The habits that compound rather than the micro-optimizations that do not. I took that seriously and restructured my practice around it. I began focusing on mechanical execution: the specific motor habits that separate players who win fights from players who win games. I expected the rating to reflect the improvement within a few hundred games.
Instead, my rating dropped 270 points over the next six months.
What I did not know (and what the ladder cannot tell you) is that my behavioral data had been recording something the rating system was not designed to capture. Concurrent Task Management, the construct most sensitive to mechanical execution fluency, had crashed to its lowest value in four years precisely at the moment I started trying to improve it.
Then, nine months later, it recovered. The rating is now beginning to follow.
I am a measurement scientist. I study how measurement systems produce the evidence that justifies decisions, and when they fail to. For five years I have been building behavioral measurement tools for StarCraft II players. This is the first time I have reported what those tools say about me, and what they say about the gap between the number on your profile and the thing that number is supposed to represent.
One other credential worth disclosing: I have been a StarCraft player longer than I have been a research psychologist. I finished my dissertation in 2003. I started playing StarCraft 1 in 2000. If it weren’t for StarCraft, I might have finished in 2001.
My handle is Elderbury. I play Terran on the North American server. I have never been higher than Gold league. As of this writing my MMR is locked at 2041, solidly Gold, with no imminent threat of promotion. That is the record. What follows is what the data say about it.
Sample description
Everything that follows is derived from my personal replay archive, not the research corpus described in earlier posts.
Games: 5,889 replays, all 1v1, all Terran games on the NA server
Date range: April 5, 2021 through March 20, 2026 (5 years, 11 months)
Leagues represented: Bronze through Gold, the complete range of leagues I have occupied. I have never held a Platinum rank
MMR range: Approximately 1,827 (minimum) to 2,507 (maximum)
Matchups included: TvT, TvZ, TvP, with no filtering by matchup for this analysis
Exclusions: Games under 5 minutes duration are excluded from behavioral analysis. Observer-perspective replays are excluded. This removes 49 games, leaving a behavioral analysis sample of 5,840 games
MMR values are matched to replay timestamps using the SC2Pulse API. The API returns a rolling MMR estimate rather than a per-game result; the matched value is the nearest recorded MMR observation within a 24-hour window of each game timestamp. Where no match is available within 24 hours, the game is retained for behavioral analysis but excluded from MMR-correlation analyses.
The pipeline producing these results is the same pipeline described in previous posts: GP1 through GP5 with IRT calibration applied to the optimal corpus (N=13,638 player-game observations, 8,297 replays, race-stratified). Construct scores reported here are IRT theta estimates produced by applying those calibration parameters to my personal feature matrix. They are on a standardized scale; zero represents the population mean, positive values represent above-average behavioral expression of the construct, and negative values represent below-average.
Three constructs are measured. Each is described briefly here and in detail in the post on behavioral constructs.
Attentional Control (AC): Whether camera attention is distributed across simultaneous demands or fixated on the most recent event. The failure mode is losing your natural expansion to nine Zerglings while your bio ball wins a fight you were watching too long.
Concurrent Task Management (CTM): Whether parallel production threads remain active when something complex demands focus. The failure mode is winning the fight and losing idle barracks, capped Orbital Command energy, and thirty seconds of SCV production time.
Decisional Commitment (DC): Whether commitment timing is crisp when information supports action. The failure mode is moving out, seeing something slightly uncomfortable, pulling back to your third, and watching an uncontested expansion go up.
Five years of rating history
Figure 1 shows my raw MMR-nearest values across all 5,889 games, ordered chronologically.
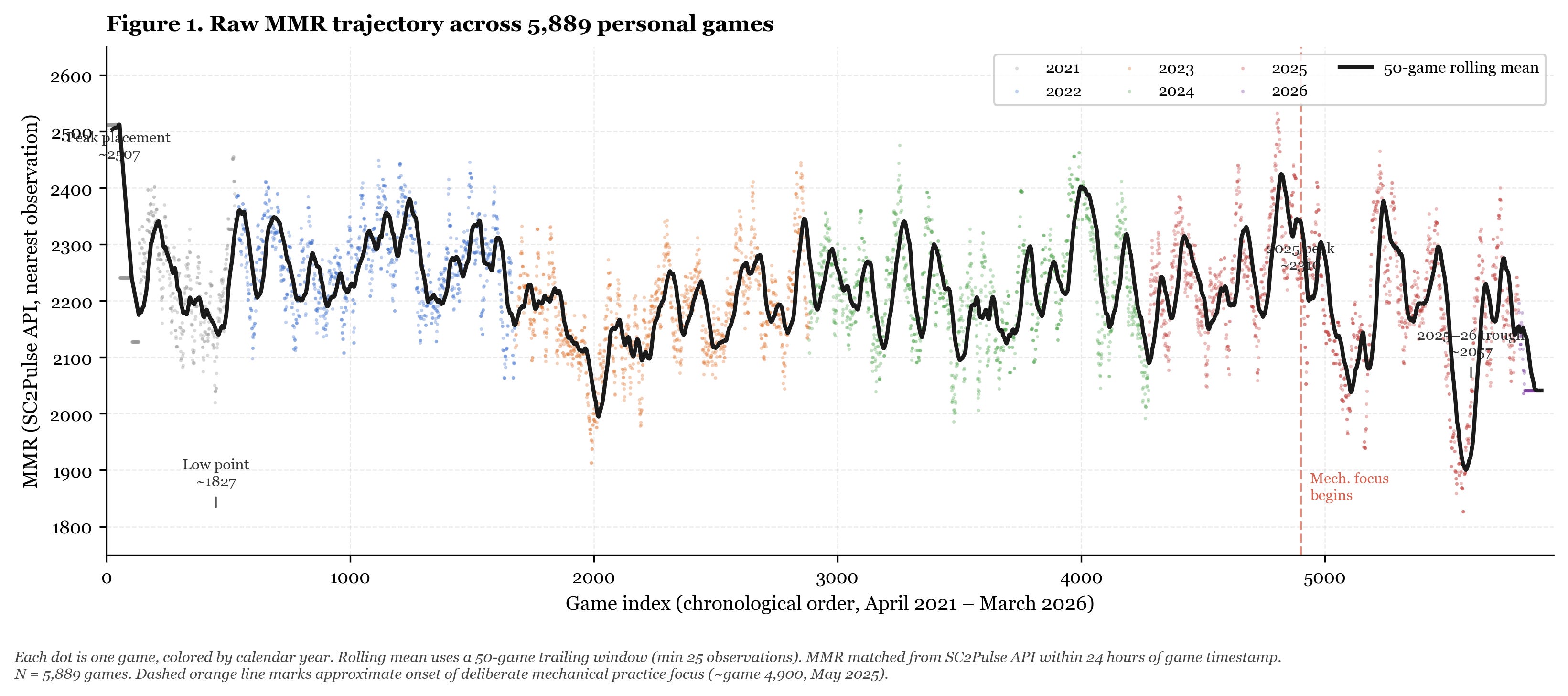
Figure 1. Raw MMR-nearest values by game index, April 2021 — March 2026 (N=5,889). Rolling mean computed over 50-game windows. Values reflect SC2Pulse API nearest-observation MMR matched within 24 hours of each game timestamp.
A few things are visible immediately. The series does not trend upward over five years. It cycles. There is a substantial early peak around game 50 (approximately MMR 2507, late April 2021; I was placed high and lost ground rapidly), a deep trough in mid-2021, a partial recovery through 2022, another decline through mid-2023, recovery through 2024, a second peak in mid-2025 around MMR 2310, and the current extended decline.
The current plateau at 2041 represents approximately a 270-point drop from the 2025 peak. That decline began around game 4,900, late May 2025.
Figure 1b shows the same data aggregated by quarter, which makes the multi-year cycle structure easier to read.
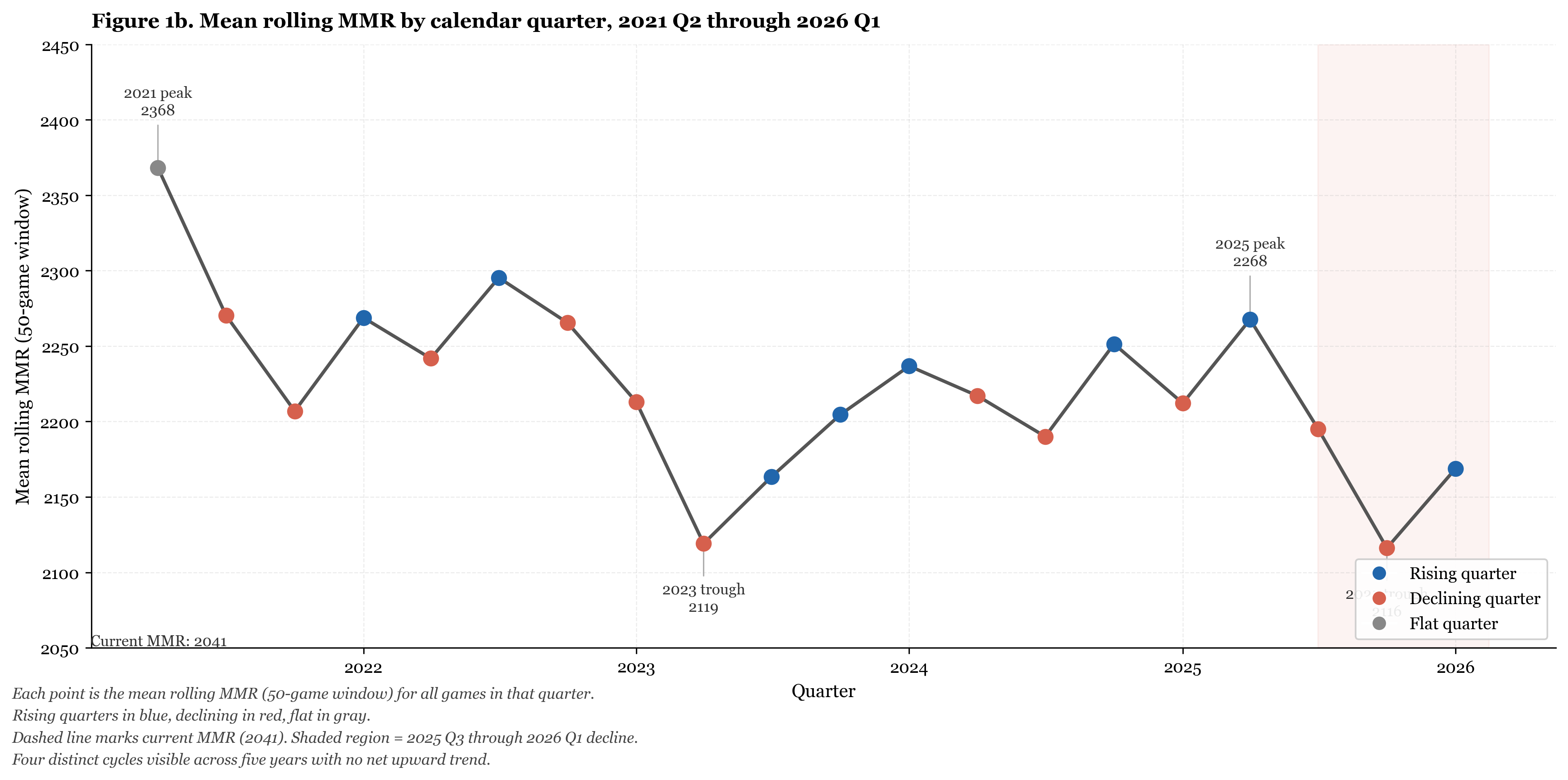
Figure 1b. Mean rolling MMR by calendar quarter, 2021 Q2 through 2026 Q1. Rising quarters shown in blue, declining in red. Dashed line marks current MMR (2041). The series shows four distinct cycles across five years with no net upward trend.
The series does not trend upward over five years. It cycles. Four distinct peaks and troughs are visible across the window, and the current rating sits close to where the series began. This is the complete picture that ladder alone provides.
Behavioral constructs across the same period
Figure 2 shows the rolling construct scores for AC, CTM, and DC across the same game series.
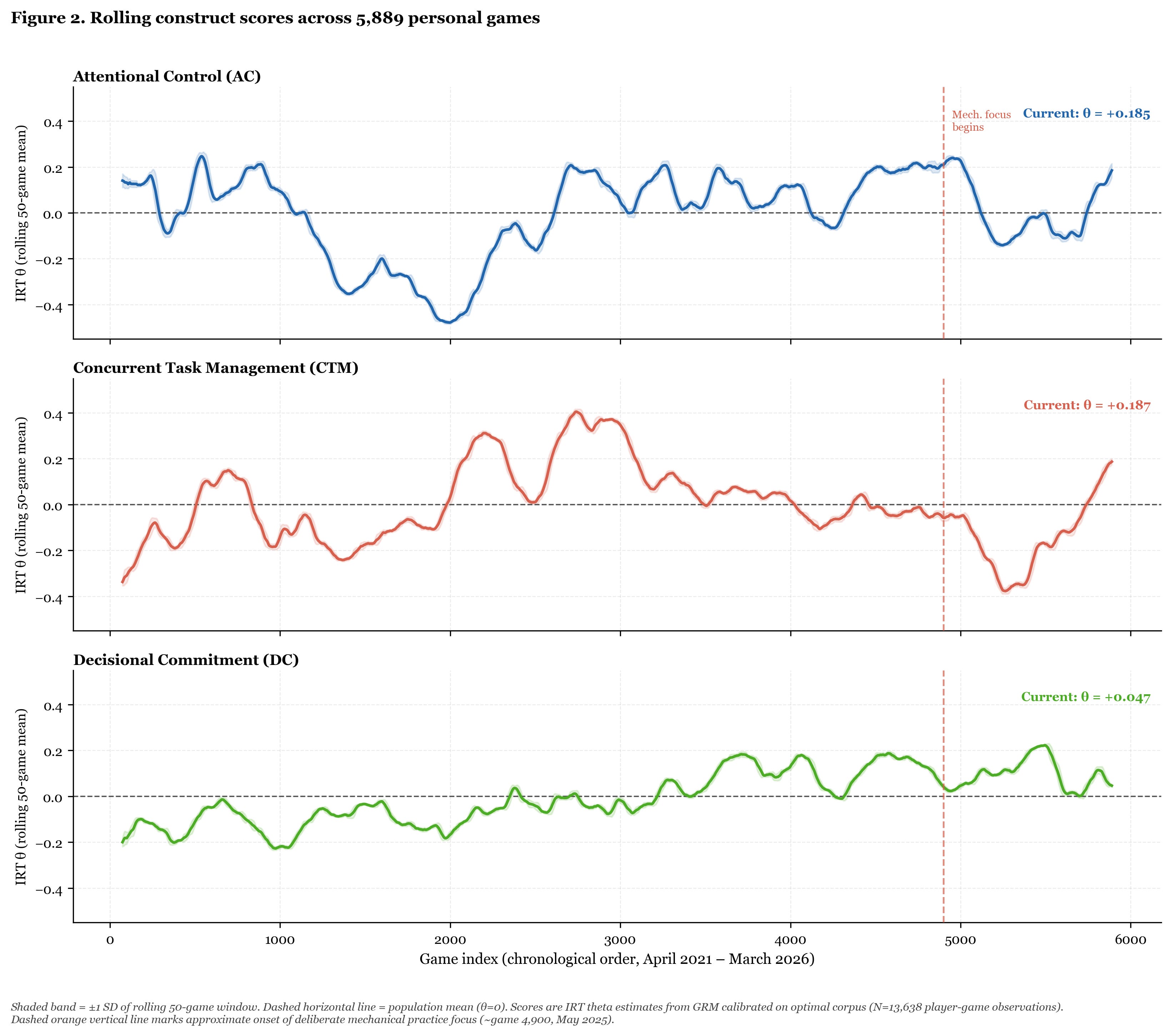
Figure 2. Rolling 50-game mean construct scores (IRT theta) by game index. Dashed horizontal line indicates population mean (θ=0). Red vertical line marks approximate onset of deliberate mechanical practice focus (~game 4,900, May 2025).
CTM is the construct to watch. From approximately game 4,700 through game 5,200 (roughly May through August 2025), CTM drops to its lowest sustained values in the entire five-year series. Then it recovers. By early 2026 it is at its highest sustained positive value since 2022.
AC shows a similar but less extreme pattern: a dip in Q3/Q4 2025, recovery into 2026Q1.
DC has been gradually rising since mid-2024 and continues rising through the current data.
The quarterly means make this visible numerically.
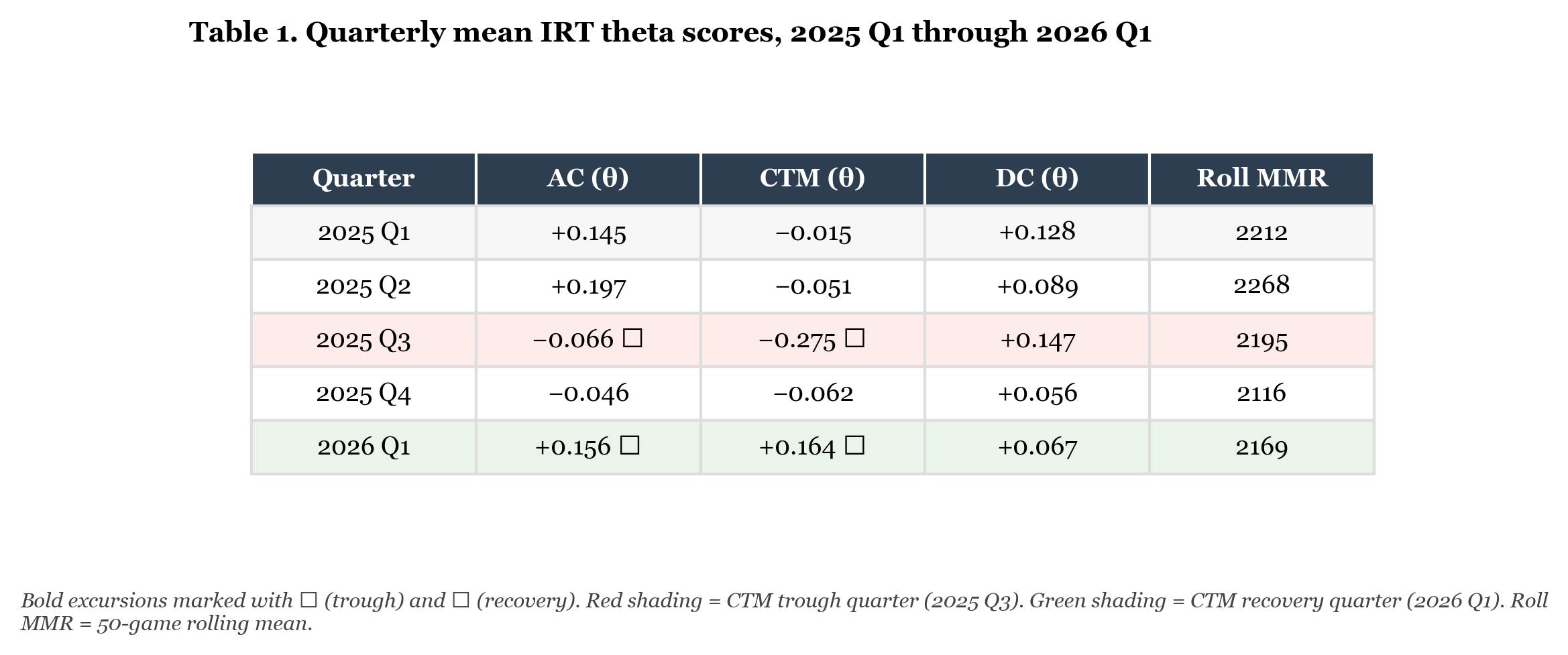
Table 1. Quarterly mean IRT theta scores by construct and quarter, 2025 Q1 through 2026 Q1. Bold values indicate notable excursions from surrounding quarters.
CTM in 2025Q3: -0.275. For context, this is the lowest quarterly CTM mean in my personal dataset going back to 2021. The previous low was 2022Q3 at -0.245 during a different period of elevated game volume.
CTM in 2026Q1: +0.164. This is the highest positive quarterly CTM mean since 2023Q4 (+0.338). The 2023Q4 peak has a straightforward explanation: I was working through PiG and uThermal’s Bronze to GM series during that period and focusing explicitly on macro fundamentals: production consistency, supply management, Orbital Command discipline. The behavioral record shows the same signature as the 2025 mechanical focus period, compressed into a single quarter. Two deliberate practice interventions, two years apart, both legible in the same construct.
The gap between the 2025Q3 trough and the 2026Q1 peak is 0.44 standard deviation units, accumulated across approximately 550 games and nine months.
What CTM measures and why a mechanical focus would affect it
CTM measures whether parallel execution threads remain active under cognitive load. In concrete Terran terms: are your barracks queuing units while your army is moving? Are your SCVs continuing to mine while you make a production decision? Is your Orbital Command not sitting at full energy because you forgot to scan or drop a mule?
Deliberate mechanical practice means attempting to execute harder patterns than you currently execute reliably. You add a new habit (say, consistent bio rallying after each supply depot) while also maintaining everything else. The early phase of any new habitual execution pattern degrades adjacent behavior temporarily. This is not a defect of practice. It is how motor learning works, and has been documented extensively in the skill acquisition literature going back to Fitts and Posner’s stages of learning (1967) and formalized in Ericsson et al.’s deliberate practice framework (1993).
What the CTM signal shows is consistent with this mechanism. During the period I identified as the beginning of my mechanical focus, CTM fell sharply. This is the behavioral signature of adding execution complexity before it integrates. The threads that were previously automatic became expensive while the new pattern competed for attention.
AC shows a milder version of the same pattern, which also makes sense. If CTM load is elevated, attentional resources available for systematic camera cycling decrease.
What did not degrade is DC. Decisional Commitment has been rising steadily and continued rising through the mechanical focus period. This is the one construct that does not depend on mechanical fluency. It measures timing, not execution quality.
The deliberate practice signature in figures
Figure 3 isolates the period of interest, 2024Q4 through 2026Q1, and shows both the behavioral trajectory and the rating trajectory on the same time axis.
Figure 3. Rolling 50-game CTM score (left axis) and rolling MMR (right axis), games 4,500–5,889. CTM trough precedes MMR trough by approximately one quarter. Both are recovering as of 2026Q1.
The timing matters. CTM reached its lowest point approximately in August 2025 (around game 5,100). The MMR trough, the period of lowest sustained rating, came approximately in November 2025 (around game 5,600). The behavioral signal led the outcome measure by roughly one quarter.
This is not a causal claim. The MMR decline had multiple contributors and I am not in a position to fully decompose them. But the sequence is consistent with the deliberate practice hypothesis: behavior degrades first, performance outcome degrades with a lag, then behavior recovers, and the outcome begins recovering after.
As of the current data (late March 2026), CTM is at +0.164, AC is at +0.156, and DC is at +0.067. The rolling MMR is at approximately 2169 and the raw MMR has been locked at 2041 for several weeks. The behavioral data are ahead of the rating data, as they have been before.
Two different constructs are doing two different kinds of work in this story, and it is worth being explicit about that before turning to the lag analysis. CTM is the disruption signal: it tracks the cost of adding new execution patterns before they integrate, and it moves with the rating decline on a roughly contemporaneous basis. AC is the recovery signal: it predicts where the rating is heading rather than where it currently is. These are not contradictory findings. They are descriptions of two different behavioral phenomena operating at two different timescales. The lag analysis below makes the distinction numerically precise.
Construct-MMR correlations are not constant
One finding from this dataset that did not appear in the population-level analysis deserves its own treatment: the correlation between behavioral constructs and MMR depends entirely on what regime the system is in.
The longitudinal analysis categorizes each game into a behavioral regime based on the rolling construct trajectory at that point. The regime categories are: acquisition_rising, consolidation, high_plateau, mixed, rebound, stable, suppressed_declining.
Table 2 shows the Spearman correlation between each construct’s rolling score and rolling MMR, computed separately within each regime.
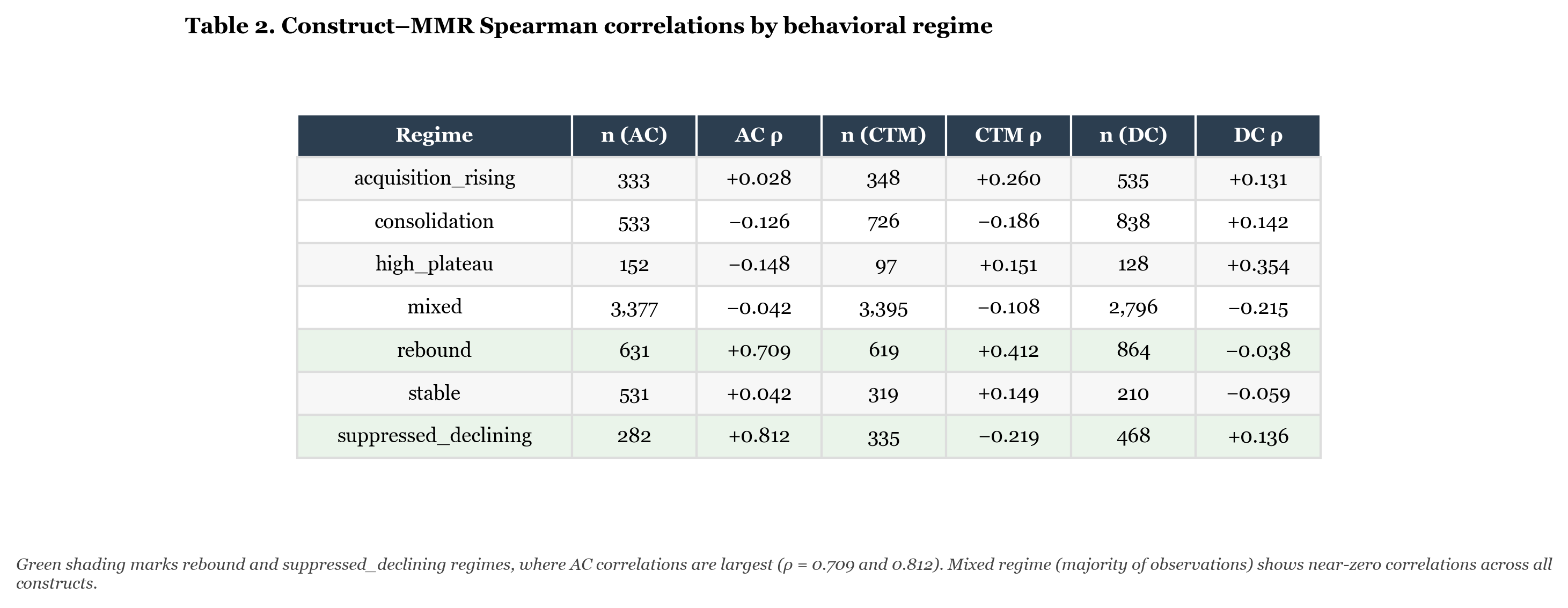
Table 2. Spearman correlation between rolling construct score and rolling MMR, computed within each behavioral regime. N values indicate the number of game observations classified in each regime for each construct. The mixed regime accounts for the majority of observations (3,377–3,395 games, approximately 58% of the behavioral analysis sample).
Figure 4 displays these correlations visually.
Figure 4. Regime-conditional Spearman correlations between construct scores and MMR. The mixed regime (majority of observations) shows near-zero to weakly negative correlations across all constructs. Extreme correlations emerge only during suppressed_declining and rebound regimes.
The finding is stark. In the mixed regime, where 58% of my games fall, the correlation between any construct and MMR is close to zero. The behavioral measurements are essentially uninformative about where the rating is heading during ordinary play.
During the suppressed_declining and rebound regimes, AC becomes highly informative: ρ = 0.812 and 0.709, respectively. These are not modest correlations. They indicate that AC trajectory is closely coupled to MMR trajectory precisely when the system is transitioning, whether declining or recovering.
This has a practical interpretation. Attentional Control is not a useful predictor during stable play. It becomes a useful predictor exactly when something is changing. If AC is rising during a period when your rating is suppressed, this dataset suggests you are more likely to be in a rebound condition than a continuing decline.
That is, of course, what my current data show. AC is at +0.156, rising. Rating is at 2041, flat. AC is ahead of the outcome measure, as it was during the recovery period visible in 2023Q4 through 2024Q1.
Lag structure: does behavior predict future rating?
The regime analysis addresses conditional correlations within periods. A separate question is whether behavioral scores at time T predict MMR at time T+k, averaging across all conditions.
Table 3 shows Spearman correlations at lag-0 (contemporaneous) and lag-100 (behavioral score at game i correlated with MMR at game i+100) for each construct.
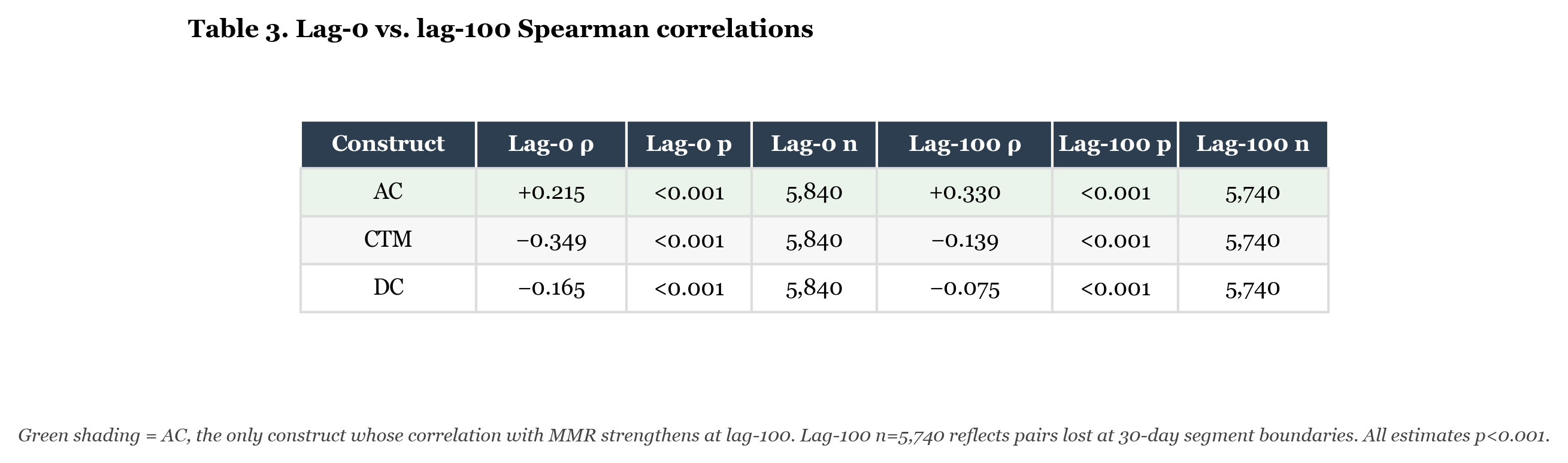
Table 3. Spearman correlations between construct scores and MMR at lag-0 (contemporaneous) and lag-100 (behavioral score compared to MMR 100 games later). Lag-100 n=5,740 reflects pairs lost at segment boundaries where gaps in the play record exceed 30 days. All estimates significant at p<0.001.
Three observations on this table.
First, the sample sizes. Lag-0 uses all 5,840 valid games. Lag-100 uses 5,740; the 100-game reduction reflects pairs lost at the boundaries of contiguous play segments when gaps in the record exceed 30 days. This is structural, not data loss. With n=5,740 the lag-100 estimates are stable and all clear p<0.001.
Second, AC. It is the only construct whose relationship with MMR strengthens at lag-100: from ρ = +0.215 contemporaneously to ρ = +0.330 at 100 games forward. Higher AC today predicts higher MMR 100 games from now more strongly than it predicts higher MMR right now. This is the leading-indicator result. It holds across the full five-year series at robust sample sizes.
Third, CTM and DC. Both are negative at lag-0 and remain negative at lag-100, but attenuate substantially: CTM from -0.349 to -0.139, DC from -0.165 to -0.075. Being low on CTM or DC today is more predictive of low MMR today than of low MMR 100 games from now. The negative relationship decays over 100 games. This is consistent with CTM and DC measuring transient process states, conditions that change, rather than fixed skill levels. The deliberate practice period is the concrete illustration of this: CTM was low, but the low value did not persist and did not permanently suppress the rating.
Figure 5 shows all three relationships visually.
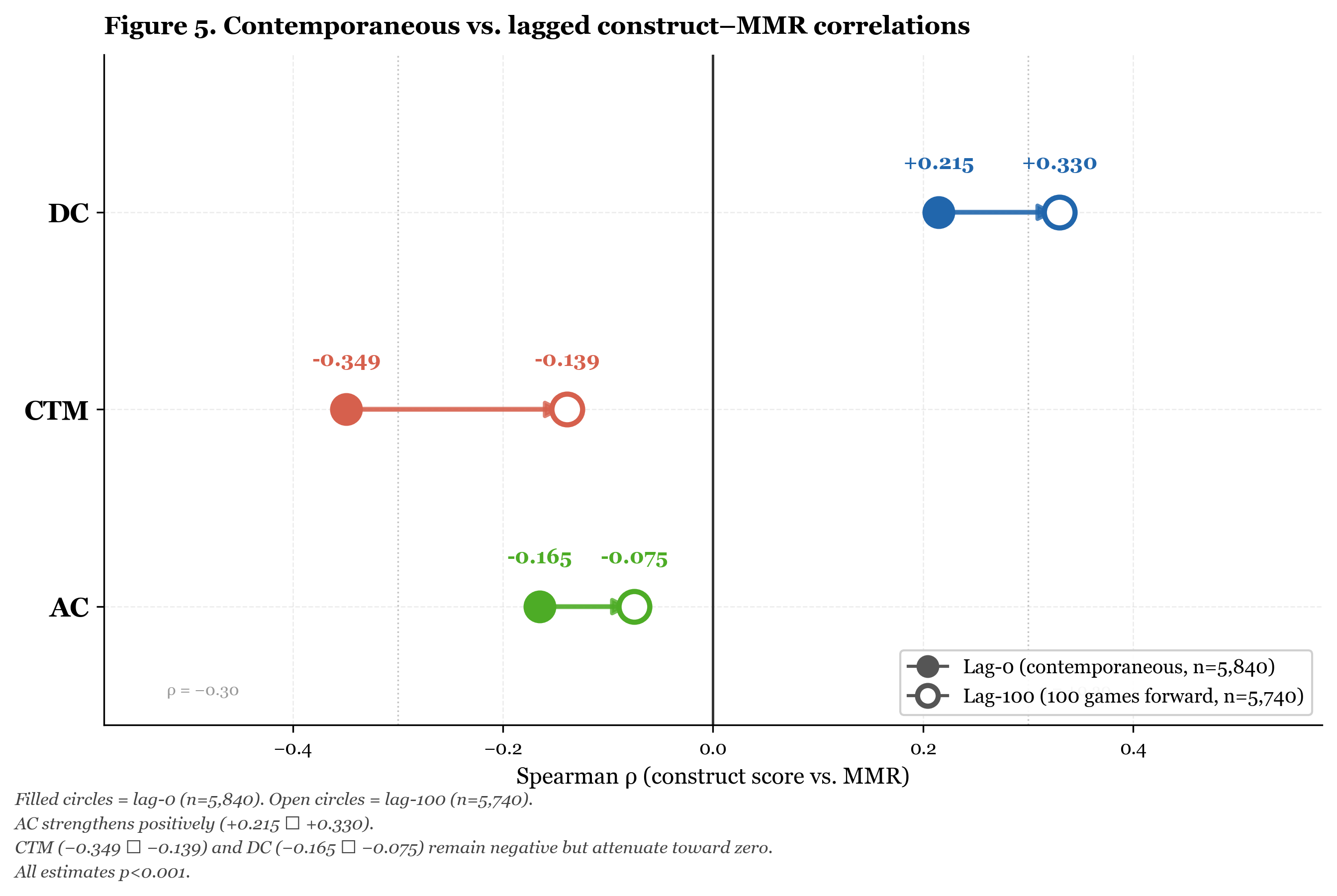
Figure 5. Contemporaneous (lag-0, n=5,840) and lagged (lag-100, n=5,740) Spearman correlations between construct scores and MMR. AC strengthens positively (+0.215 → +0.330). CTM (−0.349 → −0.139) and DC (−0.165 → −0.075) remain negative but attenuate toward zero. All estimates p<0.001.
What this means and what it does not
I want to be explicit about the limits of this analysis before drawing interpretive conclusions.
This is a single-player dataset. The regime correlations, lag structures, and quarterly patterns reported here are derived from one Terran player on the NA server across five years of Bronze-through-Gold play. I cannot claim these patterns generalize to other players, other races, or other leagues without population-level replication. The population-level dataset (N=13,638, 8,297 replays, stratified across seven leagues and three matchups) exists for exactly that purpose, and that analysis is ongoing.
The regime classification is based on rolling behavioral scores, not on independent external labels. The suppressed_declining regime is defined by a behavioral criterion derived from the same constructs being correlated against MMR. This creates a circularity risk that a reader is right to flag. Interpreting the high within-regime correlations requires acknowledging that the regime assignment and the construct score are not independent; they are derived from the same underlying data. The correct interpretation is that certain behavioral trajectories are associated with specific MMR trajectories, not that the behavioral signal causes the MMR trajectory.
The deliberate practice interpretation is a hypothesis, not a confirmed mechanism. I know, from my own records, that I began focusing on mechanical execution improvements beginning approximately May 2025. The CTM decline observed from that period onward is consistent with that account. I cannot rule out other explanations: schedule changes, opponent pool differences, or seasonal MMR inflation effects.
With those caveats stated: the data are not consistent with a simple “getting worse” interpretation of the late-2025 period. The construct that most directly measures mechanical execution fluency (CTM) declined and then recovered. The construct measuring commitment timing (DC) rose throughout. The construct measuring attentional distribution (AC) dipped and recovered. The MMR decline followed the behavioral decline, not preceded it. And as of early 2026, behavioral scores have recovered ahead of the rating.
The question the data raise
The ladder provides one answer to “how am I doing?” It is an outcome measure. It reflects results: accumulated wins and losses against the matchmaking pool. It is calibrated slowly by design.
Behavioral data provide a different answer. They reflect process: what you are actually doing inside the games, independent of whether those games are won or lost. They are not inherently better than the outcome measure. But they are measuring something different.
When both measures agree, the interpretation is straightforward. When they disagree, when the behavioral signal is recovering while the rating is still falling, or vice versa, the disagreement is information. Deciding which source of evidence to trust, and for what purpose, is a measurement problem.
Most players have access to one of these measures. It is the one on their profile page.
The behavioral data have been telling a consistent story for the past nine months. The rating is catching up.
Data and methods note for technical readers
Construct calibration: IRT Graded Response Model (Samejima, 1969), calibrated on the optimal corpus (N=13,638 player-game observations, 8,297 replays, race-stratified across TvZ, TvT, PvT at seven league levels from Bronze through Grandmaster). Calibration parameters were applied to personal feature vectors to produce theta estimates. All features passed GP5 validation against SC2ReplayStats external ground truth; APM divergence from SC2ReplayStats is a known methodological difference documented in the measurement contract (personal APM computed using eight canonical event types; SC2ReplayStats uses a different event set).
Data sources: MMR history retrieved via the SC2Pulse API (nephest.com). External ground truth validation used SC2ReplayStats. Replay parsing via sc2reader.
References:
Ericsson, K. A., Krampe, R. T., and Tesch-Römer, C. (1993). The role of deliberate practice in the acquisition of expert performance. Psychological Review, 100(3), 363–406.
Fitts, P. M., and Posner, M. I. (1967). Human performance. Brooks/Cole.
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika Monograph Supplement, 34(17).
Rolling statistics: All rolling values in figures use a 50-game trailing window. Windows with fewer than 25 valid observations are excluded.
Regime classification: Based on rolling score trajectory relative to rolling standard deviation thresholds. Regime boundaries are defined in the measurement contract. The suppressed_declining regime requires sustained below-mean rolling scores with negative rolling slope; rebound requires reversal from suppressed_declining. Full regime specification available on request.
Lag analysis: Spearman correlation between construct score at game index i and MMR at game index i+k, computed over all valid pairs. A valid pair requires both observations to exist within a play segment uninterrupted by gaps exceeding 30 days. This criterion produces n=5,740 for lag-100. Relaxing the threshold to 60 days increases n but introduces potential confounds from seasonal MMR recalibration.
Code: All analysis code is available on request. The pipeline is written in Python using sc2reader, pandas, scipy, and the graded response model implementation in PyMC.
Next post: surfacing the framework that produced these constructs and why the question “which measure should I trust?” turns out to have a formal answer.